1、前言
上篇我们了解了Pony ORM框架的基本用法,今天我们一起来学习下pony的left-join。
left-join使我们日常工作中用的最多的多表联合查询语句,左连接即有两个表A、B,A的keya是B的keyb的外键,那么我们可以通过left-join将B表左连接到A表的左边,通过A表的keya找到能够匹配到keyb的B表内容,未匹配成功的行使用None(null)填充。这样就实现了左连接的查询。
左连接以左表为主,所以左表未匹配成功的行使用None填充。但是结果表的字段我们可以根据自己的需要去选择A表或者B表的字段组合完成。
2、快速开始
2.1、理论分析
我们继续使用上篇的数据库表,对于person和car两张表,person的cars和car的关系是一对多;而car的owner和person的关系是一对一。
当我们需要查询哪些车有主人,即哪些人有车时,就需要用到person left-join car;
注意:查询结果以car表为主,即未匹配成功的数据将会被None填充。另,car中owner无数据的将会被过滤掉。
2.1.1、原始表
person表:
# person表:
# 13 phyger-0 18
# 14 phyger-1 18
# 15 phyger-2 18
# 16 phyger-3 18
# 17 phyger-4 18
# 18 phyger-5 18
# 19 phyger-6 18
# 20 phyger-7 18
# 21 phyger-8 18
# 22 phyger-9 18
# 23 phyger-10 18car表:
# car表
# 1 byd 宋Pro-Dmi NULL
# 2 吉利 星越L 13
# 3 哈佛 H6 132.1.2、person left join car
# person left-join car 之后:
# p.id ---------------------------------- c.owner
# 13 phyger-0 18 1 byd 宋Pro-Dmi NULL(x)
# 14 phyger-1 18 2 吉利 星越L 13 (√) //和13匹配成功一条
# 15 phyger-2 18 3 哈佛 H6 13 (√) //又和13匹配成功一条
# 16 phyger-3 18
# 17 phyger-4 18
# 18 phyger-5 18
# 19 phyger-6 18
# 20 phyger-7 18
# 21 phyger-8 18
# 22 phyger-9 18
# 23 phyger-10 182.1.3、p的id和c的owner匹配后
# on p.id==c.owner 匹配之后:
# p.id ---------------------------------- c.owner
# 13 phyger-0 18 2 吉利 星越L 13
# 13 phyger-0 18 2 哈佛 H6 13
# 14 phyger-1 18 ↘ 全部None补全
# 15 phyger-2 18
# 16 phyger-3 18
# 17 phyger-4 18
# 18 phyger-5 18
# 19 phyger-6 18
# 20 phyger-7 18
# 21 phyger-8 18
# 22 phyger-9 18
# 23 phyger-10 182.2、代码实现
首先,我们写一个函数去实现left-join。因为需要使用db_session去解决数据库的优雅连接问题,所以我们使用函数去做。
# left-join,结果以car表(左表)为主,结果的结构自己定义
@db_session
def lftj():
'''
@note: 左连接即将后表链接在前表的左边
@code: left_join((p, c.name) for p in Person for c in p.cars)
此段代码的意思是:
将car表连接在person表的左边,当p的id等于c的owner时,匹配成功。(即找到有车的人)
@对应的SQL:
SELECT "p", "c"."name"
FROM "person" "p"
LEFT JOIN "car" "c"
ON "p"."id" = "c"."owner"
GROUP BY "p"."id"
'''
for i in left_join((p, c.name) for p in Person for c in p.cars):
print(i)以上代码的核心就是left_join((p, c.name) for p in Person for c in p.cars),首先这段代码的返回值是一个query对象,是可迭代的;其次,left_join的第一个参数就是结果表结构,即p对象和c的name两列;for p in Person就相当于FROM "person" "p",即从Person表查询,别名为p;for c in p.cars最重要,它表达的意思就是left join Car且ON "p"."id" = "c"."owner",最终返回一个query对象。
然后我们对这个query对象进行遍历打印。
代码运行结果:
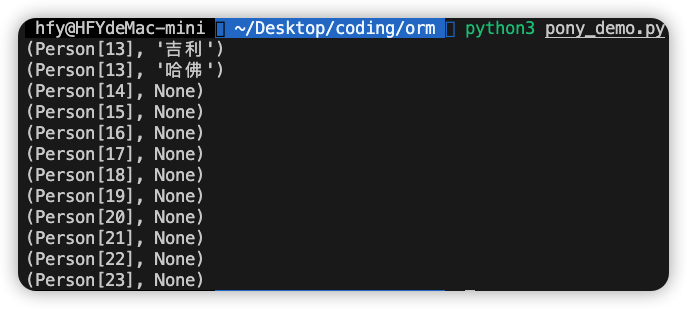
这个查询结果表示,所有车有主人的是吉利和哈佛;而且吉利和哈佛的主人都是Person[13]。
对于这个结果表结构,我们可以在left-join的第一个参数中进行定义。
...
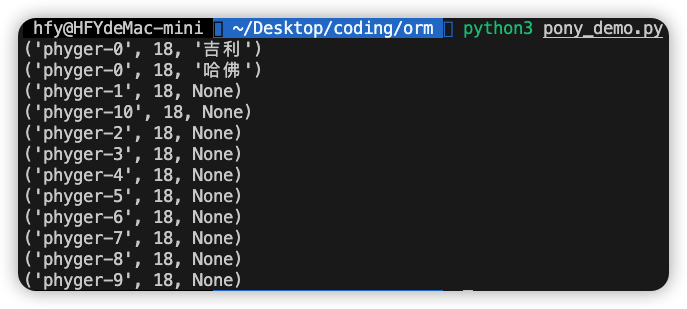
for i in left_join((p.name,p.age, c.name) for p in Person for c in p.cars):
print(i)以上代码的执行结果:
2.3、去掉None
我想实际开发中,我们经常会需要将这些未匹配成功的数据过滤掉,当然我们可以通过left-join后进行过滤,但是这样就多了一步,值得高兴的是Pony的select就可以同时实现left-join和过滤None的效果。
# 联合查询,结果是交集,结果的结构自己定义
@db_session
def xx():
for i in select((p.name,p.age, c.name) for p in Person for c in p.cars):
print(i)
if __name__ == '__main__':
db.generate_mapping(create_tables=True)
xx()通过上述代码,我们可以看到select和left-join的语法完全一样,只是结果有区别。
代码执行结果:

3、最后
其实只要了解了left-join的原理,不论我们使用何种ORM框架,其底层SQL都是一致的。