




何为用例分层?
在自动化测试领域,自动化测试用例的可维护性是极其重要的因素,直接关系到自动化测试能否持续有效地在项目中开展。
概括来说,测试用例分层机制的核心是将接口定义、测试步骤、测试用例、测试场景进行分离,单独进行描述和维护,从而尽可能地减少自动化测试用例的维护成本。
逻辑关系图如下所示:
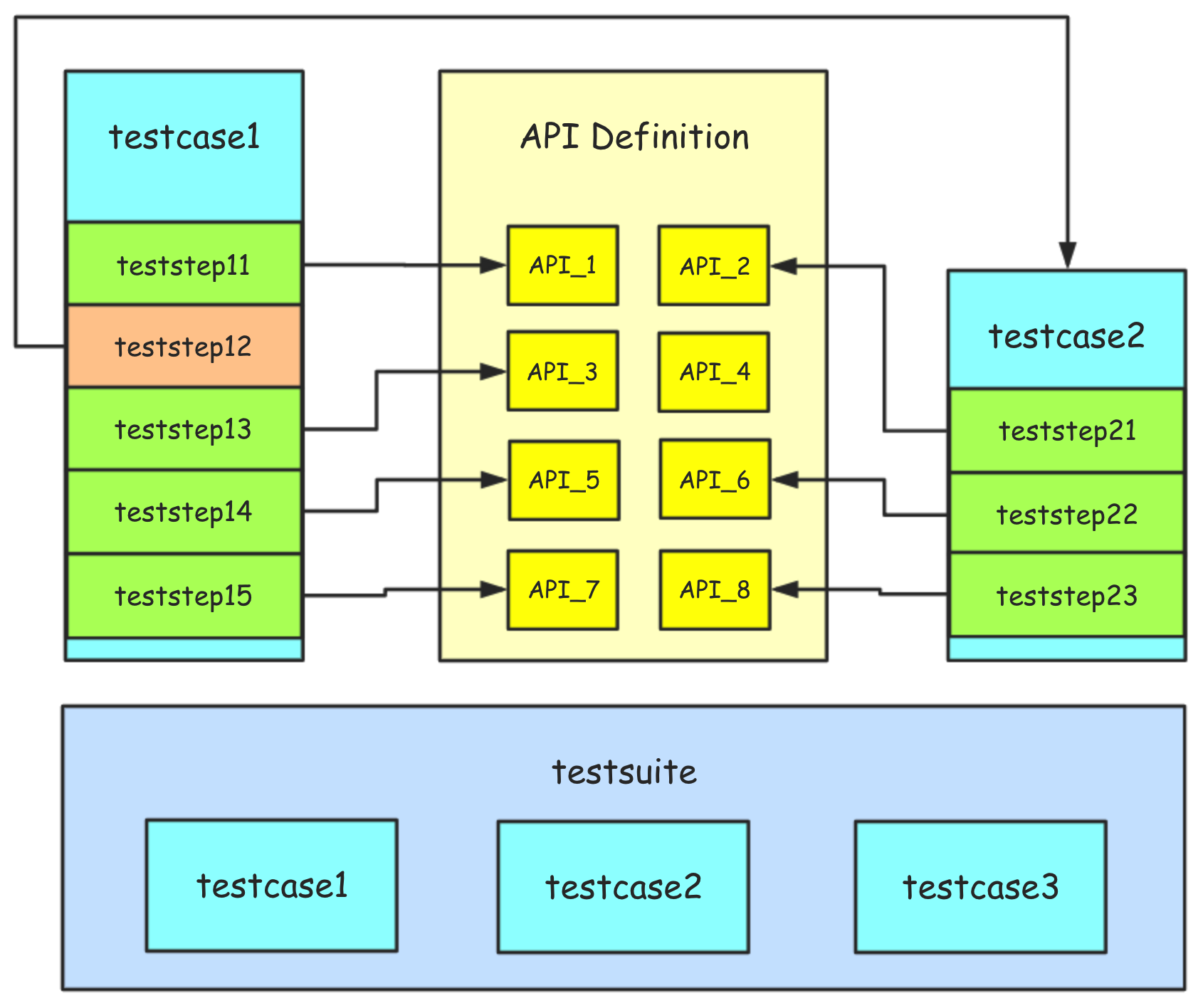
图片摘自 httprunner 官方网站。
几个核心概念
- 测试用例(
testcase)应该是完整且独立的,每条测试用例应该是都可以独立运行的 - 测试用例是测试步骤(
teststep)的有序集合,每一个测试步骤对应一个API的请求描述 - 测试用例集(
testsuite)是测试用例的无序集合,集合中的测试用例应该都是相互独立,不存在先后依赖关系的;如果确实存在先后依赖关系,那就需要在测试用例中完成依赖的处理
HttpRunner 的分层详解
第一层:接口定义
有了接口的定义描述后,我们编写测试场景时就可以直接引用接口定义了。
在测试步骤(teststep)中,可通过 api 字段引用接口定义,引用方式为对应 API 文件的路径,绝对路径或相对路径均可。推荐使用相对路径,路径基准为项目根目录,即 debugtalk.py 所在的目录路径。
为了更好地对接口描述进行管理,推荐使用独立的文件对接口描述进行存储,即每个文件对应一个接口描述。
接口定义描述的主要内容包括:name、variables、request、base_url、validate 等,形式如下:
name: get test
base_url: http://mock.cn
variables:
expected_status_code: 200
request:
url: /
method: GET
validate:
- eq: ["status_code", $expected_status_code]
- eq: [content.headers.Host, "mock.cn"]
其中,name 和 request 部分是必须的,request 中的描述形式与 requests.request(Python 的 requests 库中的 request 方法) 完全相同。
另外,API 描述需要尽量保持完整,做到可以单独运行。如果在接口描述中存在变量引用的情况,可在 variables 中对参数进行定义。通过这种方式,可以很好地实现单个接口的调试。
第二层:测试用例中的测试步骤
我们可以在测试用的测试步骤中直接引用接口定义和测试用例。
引用接口定义使用
api关键字,引用测试用例使用testcase关键字。
引用接口定义
- config:
name: "test_1"
variables:
user_agent: 'chrome 56.8'
device_sn: "ddd"
os_platform: 'chrome'
app_version: '56.8'
base_url: "http://127.0.0.1:5000"
verify: False
output:
- session_token
- test:
name: get token (setup)
api: api/api_1.yml
variables:
user_agent: 'chrome 56.8'
device_sn: $device_sn
os_platform: 'chrome'
app_version: '56.8'
extract:
- session_token: content.token
validate:
- eq: ["status_code", 200]
- len_eq: ["content.token", 16]
- test:
name: test_2
api: api/api_2.yml
variables:
token: $session_token
若需要控制或改变接口定义中的参数值,可在测试步骤中指定 variables 参数,覆盖 API 中的 variables 实现。
同样地,在测试步骤中定义 validate 后,也会与 参数化后,parameters 中的变量将采用笛卡尔积组合形成参数列表,依次覆盖 variables 中的参数,驱动测试用例的运行。 中的 validate 合并覆盖。因此推荐的做法是,在 API 定义中的 validate 只描述最基本的校验项,例如 status_code,对于与业务逻辑相关的更多校验项,在测试步骤的 validate 中进行描述。
引用测试用例
即在用例中引用用例。
- config:
name: "config_1"
id: config_1
base_url: "http://127.0.0.1:5000"
variables:
uid: 8774
device_sn: "xxx"
output:
- session_token
- test:
name: test_1
testcase: testcases/case_1.yml
output:
- session_token
- test:
name: test_2
variables:
token: $session_token
testcase: testcases/xxx/case_2.yml
测试用例集
当测试用例数量比较多以后,为了方便管理和实现批量运行,通常需要使用测试用例集来对测试用例进行组织。
测试用例集(testsuite)是测试用例的 无序 集合,依赖关系在在测试用例中完成处理。
每个测试用例集文件中,第一层级存在两类字段:
config: 测试用例集的总体配置参数testcases: 值为字典结构(无序),key为测试用例的名称,value为测试用例的内容;在引用测试用例时也可以指定variables,实现对引用测试用例中variables的覆盖。
非参数化场景
config:
name: config_suite
variables:
device_sn: ${gen_random_string(15)}
var_a: ${gen_random_string(5)}
var_b: $var_a
base_url: "http://127.0.0.1:5000"
testcases:
case_1:
testcase: testcases/case_1.yml
variables:
uid: 1000
var_c: ${gen_random_string(5)}
var_d: $var_c
case_2:
testcase: testcases/case_2.yml
variables:
uid: 1001
var_c: ${gen_random_string(5)}
var_d: $var_c
参数化场景
对于参数化场景,可通过 parameters 实现,描述形式如下所示
config:
name: config_suite
variables:
device_sn: ${gen_random_string(15)}
base_url: "http://127.0.0.1:5000"
testcases:
case_1:
testcase: testcases/case.yml
variables:
uid: 1000
device_sn: xxx
parameters:
uid: [101, 102, 103]
device_sn: [sn_1, sn_2]
参数化后,parameters 中的变量将采用笛卡尔积组合形成参数列表,依次覆盖 variables 中的参数,驱动测试用例的运行。


评论区